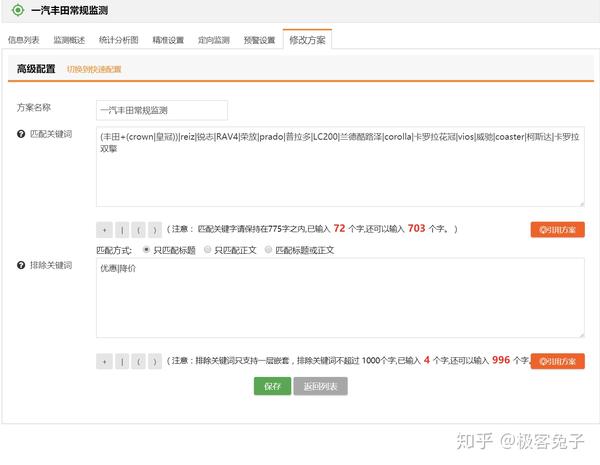
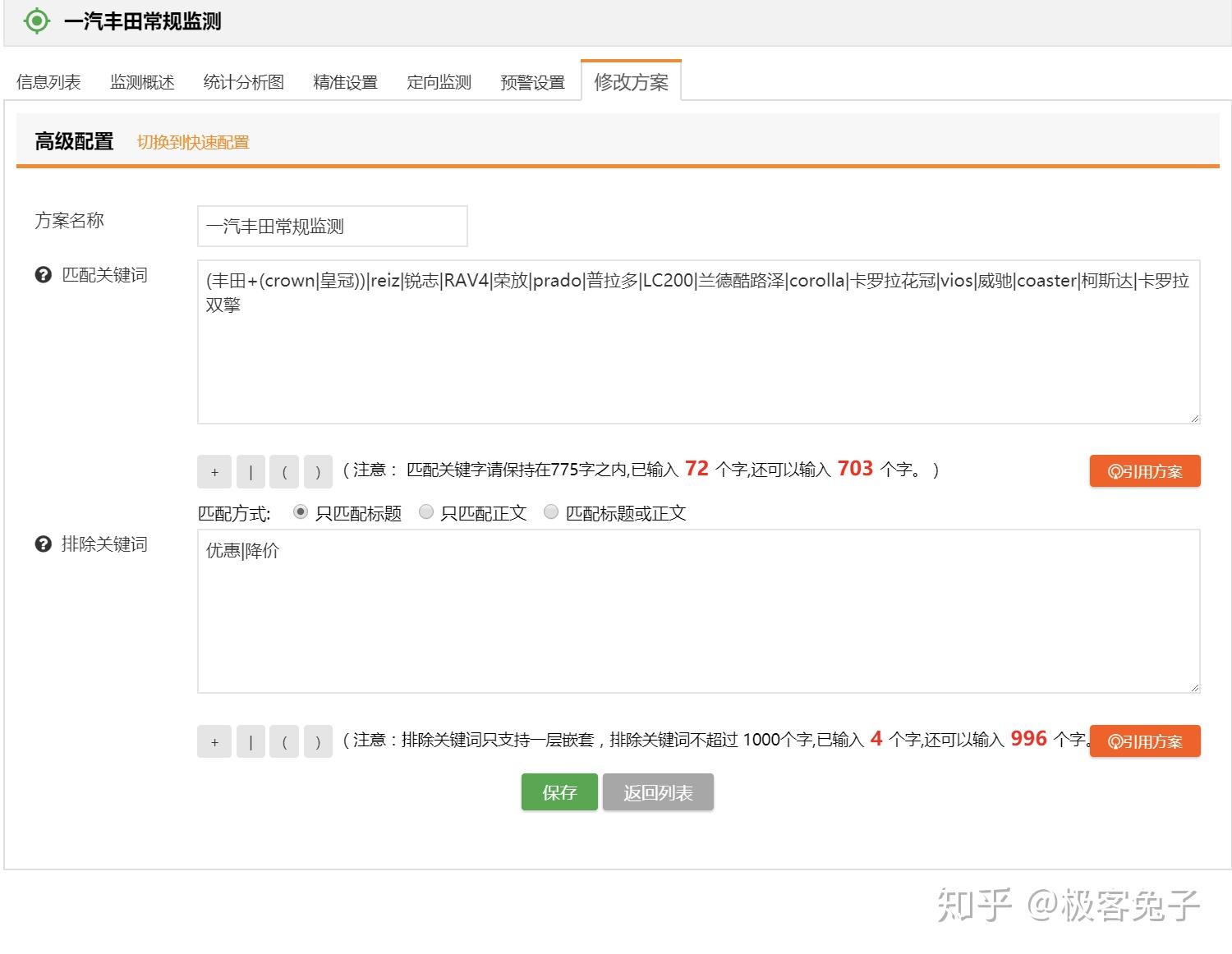
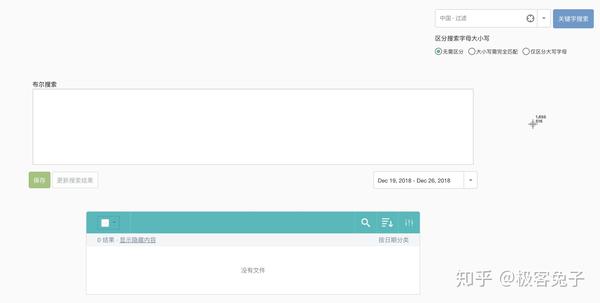
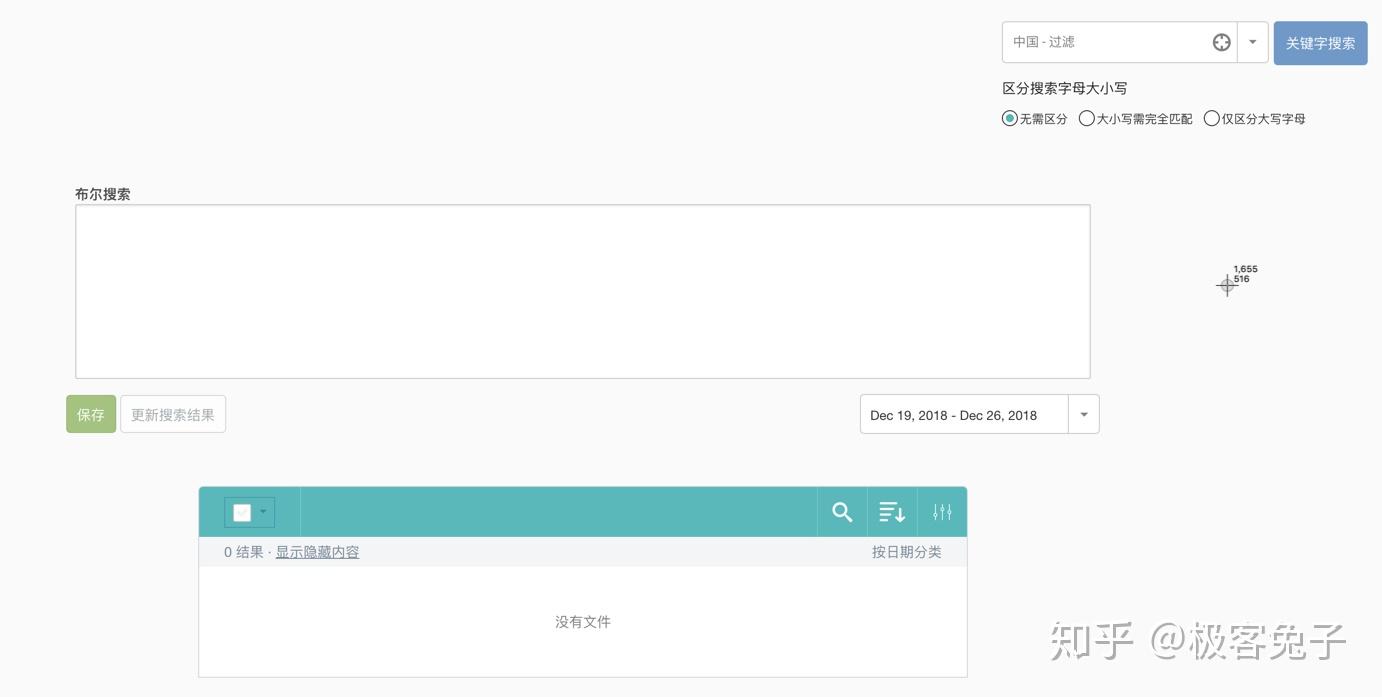
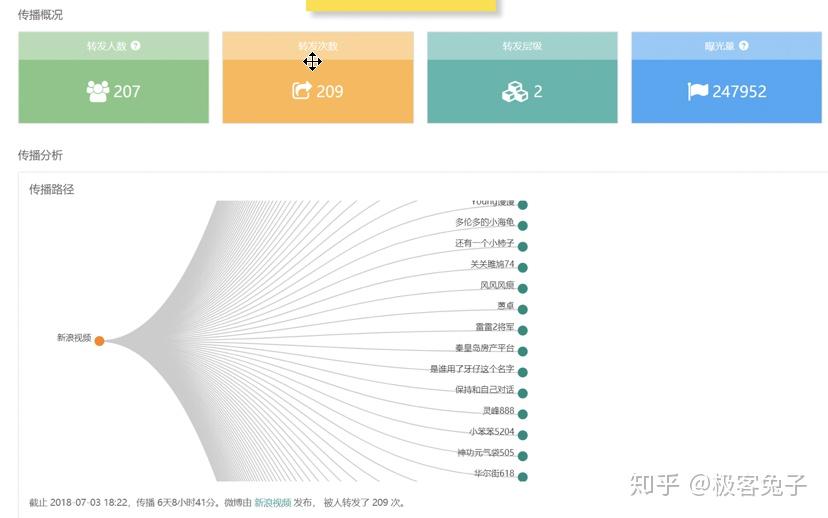
2018年我接觸了很多輿情公司,主要原因還是因為想合作拿單或者代理他們的產品,也正因為如此,對一些基礎功能和數據情況的對比感受會更明顯,到了年底最后幾天了,著手一些總結性的文章,于是就寫出了本文。 首先輿情產品的狹義,大體來說是基于輿論情報的分析,提供決策支持。其中輿論的部分比較重,因為傳統輿情產品主要是對網絡輿論的監測、預警、報告三項核心服務。如果說廣義的輿情,其實就是情報,從網絡的任何細小角落里發現蛛絲馬跡,推導出可以提供決策支持的信息、情報、知識、結論等等。 所以,如果單指傳統輿情產品,大都包含以下核心功能: 今年,傳統輿情產品大都開始加入了一些更細致的功能,一方面是因為傳統產品同質化情況過于嚴重,另一方面也是因為現階段如果只做政府輿情已經市場比較飽和了,但是突破到企業市場的時候,就不是這么簡單了。首先企業對輿情的本質需求偏低,這里通常細分成口碑輿情、品牌輿情、高管輿情等,也就是說只有部分有實力的公司愿意購買輿情系統,一般公司很可能不愿意付出多少代價來采購輿情系統。而且很多公關公司包攬了輿情產品的功能及作用,所以如果真要說的話,那就是所有的公司大都只想買個服務,并不是非要買個系統然后自己的運營人員還得學習怎么用。 那么問題就來了,既然買的是服務,服務的可能性是遠大于輿情系統自身的,服務里面有人工的作用,所以人工可以判斷一些情況,包括報告、預警、引導處置等等。但是輿情系統則需要負責的設定,包括關鍵詞組合、預警條件組合、引導處置語料配置等等。這些設置的繁瑣程度,如果是沒接觸過輿情系統的,尤其是“懶惰”的體系內人員的話,估計只有甩臉和罵街的份,只有積累了一定規則和詞庫的組織才能比較好的用起來,否則大都需要商務、運營人員介入幫助客戶來配置。 為什么輿情系統的配置一直是大家詬病而且更傾向于買個服務“全包”呢?這就要從關鍵詞規則配置說起了,目前市面上大多數系統都有一些通用的配置方法,比如: 上圖是凡聞的方法,基本策略是,包含全部(and關系),包含任意(or關系)和排除(not,and關系),也就是說(a and b and c) and (d or e or f) not (g and h and i),但是這樣的配置實際上是一個非常簡化的配制方法,很多細項功能是無法實現的。 上圖是輿情通的方案配置方法,第一層是匹配,第二層是排除,每個都支持基礎布爾表達式,包括:括號、與(+號,表示and)、或(|號,表示or),這樣就可以做一些更復雜的組合。同時這里允許選擇該表達式生效區域是標題還是正文還是全部。 上圖是Meltwater的高階布爾表達式搜索框,關鍵詞配置監測任務也是一樣的操作。這個布爾表達式的檢索邏輯以及可控制的維度可以說是比較全面的,其他公司的基本類似,包括百分點輿情、智慧星光、清博輿情、慧科等等,大都只是他們的變種或者增加了一些維度,殊途同歸。這個布爾表達式可以多復雜呢?見下圖說明。 也就是說,Meltwater的布爾表達式不僅具備了與或非關系,還支持標題匹配、邏輯順序、模糊匹配、位置關系等細分功能。但是看到這么多配置方法,再加上輿情中可能出現的詞千變萬化,每次檢索出來的數據還要大海撈針找到有價值的線索,這種工作實在不是一般人能享受過程的,所以所有市面上的輿情系統都無時不刻的在被詬病。 近年來,輿情公司應對這種客戶的詬病的方法不外乎幾種,一,由公司安排運營人員、商務人員協助配置甚至直接幫助配置關鍵詞規則;二,直接購買服務,全部操作都由運營人員操作,客戶只需要提出需求便可。至于簡化配置方法的第三條路,也就是規則庫或者詞庫一直因為客戶的跨行業、跨地域區別太大,導致停留在摸索期。積累了大量用戶操作行為之后,一些公司已經開始將詞庫進行模型訓練并建立基于深度學習技術的文本分類模型,用于輿情的下一代功能改進,比如某公司輿情分類模型已經至少可以看到二級,且覆蓋較全面。 我個人認為以后可以預見到,關鍵詞配置會進入輔助階段,而已經訓練好的模型會進入主流,只要勾選便可以直接使用,并且還可以通過用戶行為不停地優化,最終甚至引入更復雜的推薦引擎,將找到線索的可能性以及用戶體驗大幅度改進。這也是2018年輿情系統的一個重要的改進方向。 另一個比較重要的輿情系統改進方向是加強了監測類型,傳統監測類型是關鍵詞自定義監測任務、專題監測任務、事件監測任務,現在則是開始加入更精細化的人物監測任務、傳播監測任務等等。 人物監測一直是一個老生常談的監測類型,一方面因為涉及個人,有一定的隱私問題,所以盡可能不跨越那條線,主要面對公眾知名人物的正面形象問題進行把控。另一方面人物監測的方法一直是一個頭疼的事情,首先人名是不靠譜的,重名可能性很高;其次是人作為一個實體,具備很多屬性,包括出生地、居住地、現時活躍地都可能不同,職位可以有多個,身份也可以有多個,別名和昵稱都可以有多個,這是互聯網的天然優勢所在,但是導致的結果就是監測的時候會比較麻煩,準確率和召回率都會成為問題。解決方案就是通過NLP,對每個文章中的人名識別,人名最近距離的描述句法進行識別,找出描述詞-分析詞性-識別組織機構、職位-企業庫內驗證,最終識別出要監測的人物對象是否在這篇文章中,是否是本文的主要內容主體等等。通過這一系列的技術手段,才可能讓人物監測變的準確“那么一點點”,而人物的別名庫的引入,會讓召回率盡可能提高一些。雙劍合璧,才能讓人物監測變的更好用,但是說實話,考慮到非規范文章中對人物的描述信息極為缺失,人物監測在政府輿情監測上肯定不會是一項好用的功能。因為首先這是大海撈針,輿情一般不會直接出現在新聞稿中,大都是在社交平臺上滋生和蔓延,引起注意后才開始新聞稿件(這個主要是針對政府,因為一般新聞組織不會沒事亂發針對政府的負面新聞,大都是要審閱核實一下的)。那也就是說即使系統識別準確了,每天可能有大量關于某人的文章被發現了,即使情感分析判斷了一遍,也很難說工作就結束了。人判斷的因素一直存在,因為人是在做決策,系統的用戶看到了大量信息,篩選出可能會被領導注意的部分,領導再次進行決策,找出最符合該組織利益影響點的信息,決定是否需要處置。幾次篩選過程很受人的主觀因素影響,所以機器無法輕易替代,只能是個輔助。于是就產生了問題,每次篩選都會有信息丟失,丟失的信息是否有價值后續的決策人員是不知道的,而不篩選的話,大量信息又無法一一審查,每日工作量都會變得很大。所以這里就會形成一個悖論,召回率越高,數據量越大,又需要進一步篩選,未來AI技術會在這部分盡可能降低人工的繁瑣性識別工作。 還有一個在18年被重視并強化的功能是傳播鏈分析,實際情況是通過持續采集數據,分析某篇文章傳播鏈條或者某個事件的傳播軌跡。包括原創、轉載、轉發、閱讀和點贊等情況。如果數據覆蓋范圍夠大,數據量夠多的系統,可以生成樹狀或者網狀傳播圖。 例如上圖(百分點輿情),雖然這個樣例中只有一層傳播,所以沒法看出是一個樹狀結構。不過如果是分析某篇熱門文章的時候,就變成了一個從中心放射出的圓形網狀結構了。這種傳播鏈條分析對數據要求比較高,不僅要識別出文章自身,還要識別文章變種,相似相關等等,最重要的是,字段中還要識別出原創和轉載。當然這里面有一些套路和技術策略,我就不多說了,屬于業界技術小秘密。 以上就是我對2018年輿情產品的一些理解和認知。我是兔哥,輿情和公安大數據行業出身,后續主攻企業多維度數據分析和挖掘。我在知識星球上有免費和收費群,歡迎搜索“兔哥數據星球付費群”、“兔哥的數據星球免費群”,其他事宜可以知乎私信聯系我。